
The healthcare system cannot bill for treating you, nor can your insurance company decide what to pay, and the CDC aren’t able to count how many Americans had the flu last winter until somebody answers one question: What is wrong with this person?
The answer is never "diabetes" or "a broken arm" or "the flu,” because those are just words, and the healthcare system does not run on words. The system that tracks diagnoses, determines payment, feeds public health surveillance, and now powers AI tools runs on codes. Specifically, on a classification system called the International Classification of Diseases, Tenth Revision, Clinical Modification, which everyone in the industry shortens to ICD because life is too short for all those syllables.
ICD-10-CM is the language the United States uses to describe, in standardized form, every diagnosis a provider can document. If you have been to a doctor in the past decade, your visit created at least one of these codes, more likely several, and you almost certainly never saw them. They are underneath every clinical encounter you have ever had, and they shape your care in ways most patients never learn about.
This lesson is the first in a series on how medical coding works, from diagnoses to procedures to billing to the public health data that gets spit out the other end. If you read "The Engine and the Fuel," you met Dale Hammond, our fictional oil field worker in Stamford, Texas, whose fragmented medical record became a case study in what happens when AI tries to read documentation from a clinic with minimal HIM staff. Dale is coming with us through this entire course. His encounters will generate the codes we are learning, and his story will ground each concept in what happens when these systems meet a patient who lives 40 miles from the nearest emergency room.
So, what is wrong with Dale?
Three years ago, the clinic in Stamford told Dale he had Type 2 diabetes. That diagnosis, once documented by his provider, needed a code. The code assigned was E11.9.
Let's do a little dissection of E11.9, because the anatomy of this single code will teach you more about how ICD-10-CM works than a textbook chapter ever could.
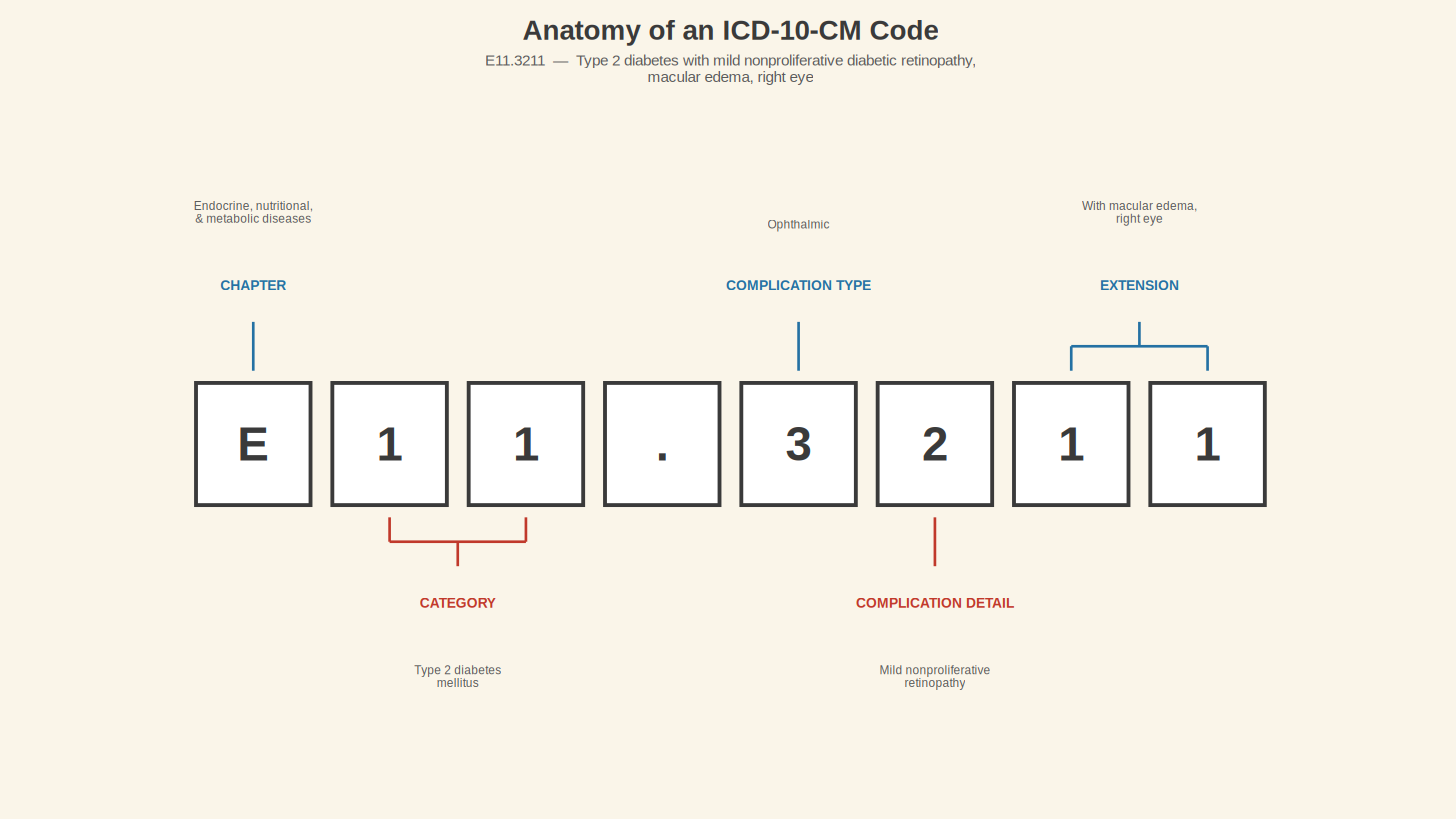
Every code starts with a letter. That opening letter tells you which chapter of the classification you are in, which is roughly equivalent to telling you which organ system or disease category the diagnosis belongs to. E places Dale's code in Chapter 4, which covers endocrine, nutritional, and metabolic diseases. You’ll also find diabetes, alongside thyroid disorders, obesity, and metabolic syndromes here. If you just have one letter, you already know the neighborhood you’re in.
Characters two and three are numbers, and together with the first letter they form the category. E11 is the category for Type 2 diabetes mellitus. A separate category exists for Type 1 (E10), for diabetes caused by an underlying condition (E08), and for drug- or chemical-induced diabetes (E09), because these conditions have separate etiologies, treatment pathways, and complication profiles. By the third character, the code has already told you which one the patient has.
These first three characters, the category, are where the broader diagnosis lives. E11 is not a billable code. You cannot submit E11 on a claim form and expect to get paid, because it is a container. Think of it as the folder. The billable codes are the documents inside.
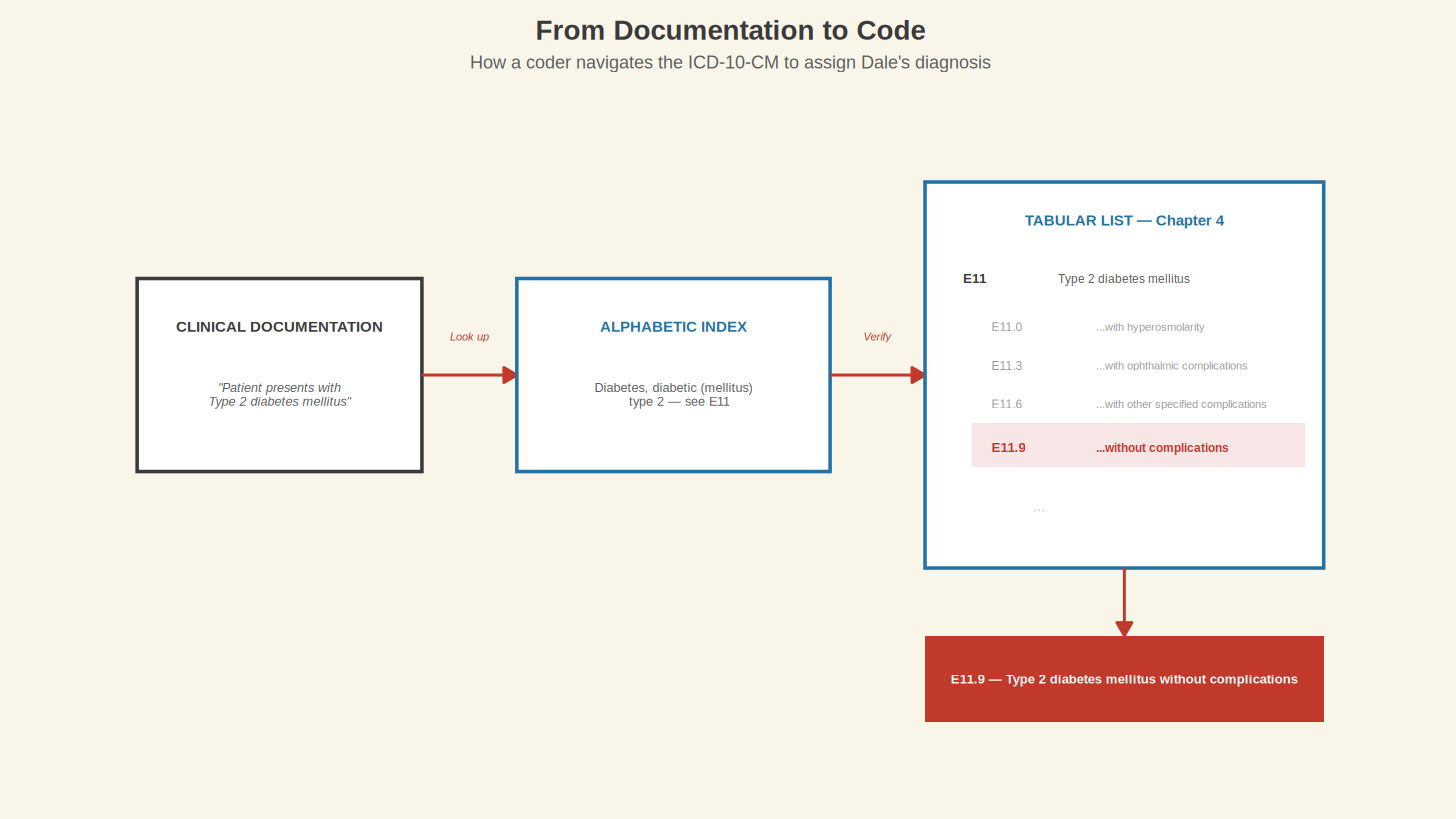
Before we go further into Dale's code, it helps to understand the system those folders live in. ICD-10-CM is organized into two sections that work together. The first is the Alphabetic Index, which lists diagnostic terms (words like "diabetes," "retinopathy," "fracture") in alphabetical order, each one pointing toward a code. Nested inside the Alphabetic Index are the Table of Neoplasms and the Table of Drugs and Chemicals, two specialized lookup tools that route specific types of diagnoses to the correct codes.
The second section is the Tabular List, which arranges every code in numerical order within 21 chapters, grouped mostly by body system or by condition type. Infectious diseases open the Tabular List in Chapter 1 (codes A00 through B99). Neoplasms fill Chapter 2. Dale's diabetes resides in Chapter 4, the endocrine chapter (E00 through E89). Diseases of the eye get their own chapter (H00 through H59), as do the ear, the circulatory system, the respiratory system, the digestive system, and so on, all the way through Chapter 21, which covers factors influencing health status and contact with health services (Z00 through Z99).

A coder reads the clinical documentation, identifies the diagnostic terms, looks them up in the Alphabetic Index to find a candidate code, and then turns to the Tabular List to verify it. That step is not optional. The Alphabetic Index does not always give you the full code; laterality, episode of care, and seventh-character extensions can only be confirmed in the Tabular List, where instructional notes tell you whether the code needs additional characters or whether a different code should be sequenced first. Skipping the Tabular List is how coding errors get made, and coding errors are how billing disputes, claim denials, and surveillance blind spots get started.
If you have the physical books (and many coding programs still train on them), the Tabular List is the thicker volume. Flipping to Chapter 4, finding the E11 block, and running your finger down the subcategories is the analog version of what the online browsers do digitally. Whether you use the books or the CDC's free browser at icd10cmtool.cdc.gov, the process follows the same logic. Start with a word, find a code, verify it in the Tabular List.
After the category comes a decimal point, and then a fourth character. In Dale's code, that fourth character is 9. In the E11 family, the fourth character specifies the type of complication. E11.0 is Type 2 diabetes with hyperosmolarity. E11.1 is Type 2 diabetes with ketoacidosis. E11.2 covers kidney involvement. E11.3 covers the eyes. E11.4 is neurological. E11.5 is circulatory. The numbers climb through the body's systems like a checklist.
E11.9, Dale's code, means Type 2 diabetes mellitus without complications. That trailing 9 is the system's way of saying that as far as the record is concerned, he has diabetes and nothing else has gone wrong yet.

Except we know from Dale's story that things have gone wrong. Six months ago, an ophthalmologist in Abilene found early signs of diabetic retinopathy. If that finding made it into Dale's primary care record (and we have reasons to wonder whether it did), the code should have changed. E11.9 should have become E11.319, which is Type 2 diabetes mellitus with unspecified diabetic retinopathy without macular edema. A fifth and sixth character appeared, and the code's meaning shifted from "diabetes, no problems" to "diabetes, with an eye complication that needs monitoring."
E11.9 and E11.319 are separated by three characters. One code says Dale has a manageable chronic condition, and the other says his diabetes is already damaging his eyes and that without intervention the damage will get worse. An insurance company looking at E11.9 has no reason to approve a retinal specialist. An AI tool reading E11.9 has no reason to flag a trend. A public health researcher counting E11.9 will never know that diabetic retinopathy was present in this patient.
Those three extra characters are where coding specificity shines. ICD-10-CM was built for this.
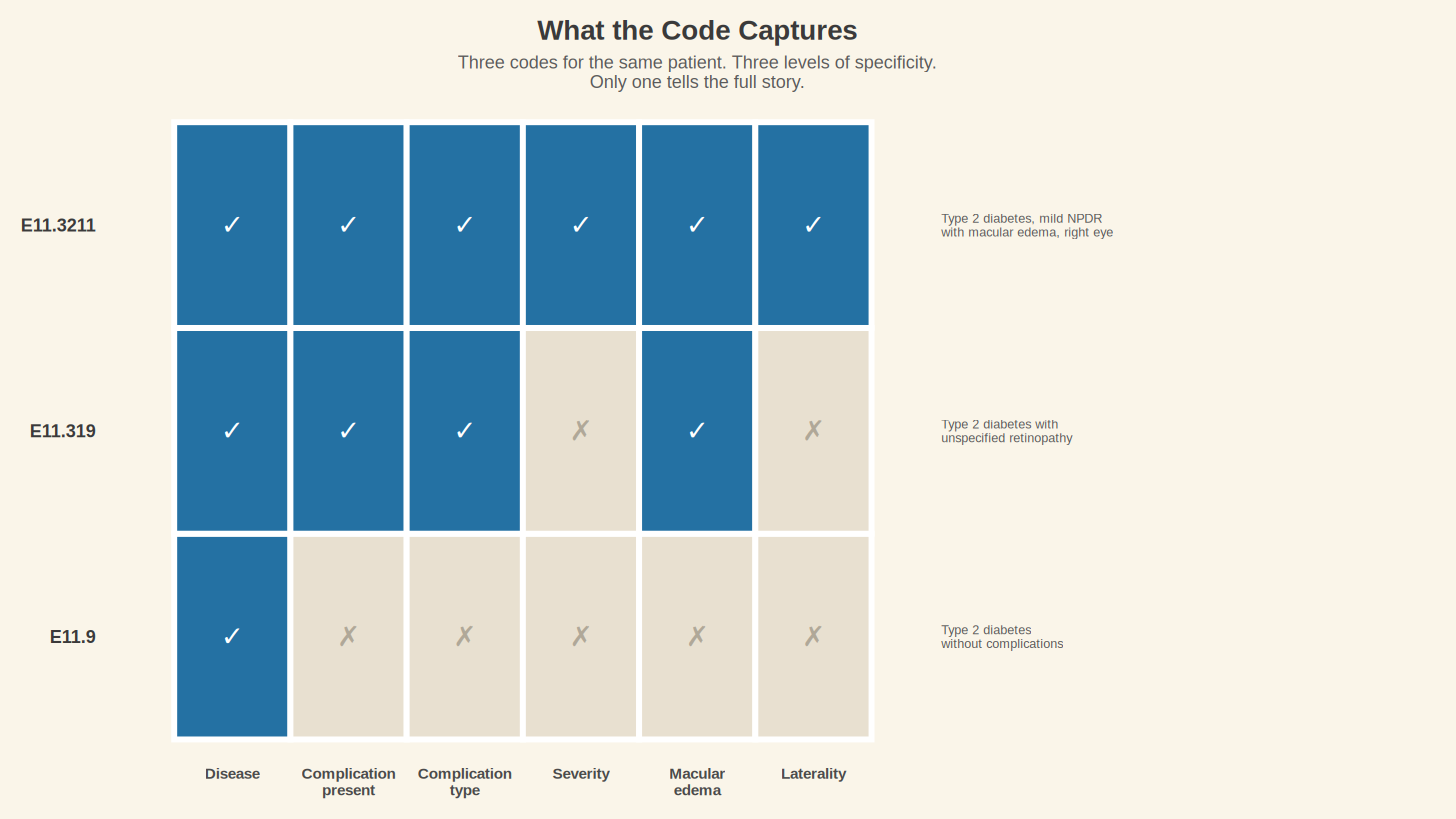
The classification system can go even further. If the ophthalmologist documented not just retinopathy but mild nonproliferative diabetic retinopathy with macular edema in the right eye, the code becomes E11.3211. Seven characters long, including the severity of the retinopathy, the presence of macular edema, and the laterality (which eye). The system has 117 distinct codes under the E11 category alone, each one describing a different permutation of Type 2 diabetes and its complications. That is 117 different answers to the question "what is wrong with this person," all living under the same three-letter header.
Try one yourself. Look at E11.65. You know E11 means Type 2 diabetes. You know the character after the decimal specifies the complication type. Based on the pattern you have seen so far (E11.0 for hyperosmolarity, E11.1 for ketoacidosis, E11.2 for kidney, E11.3 for eyes, E11.4 for neurological, E11.5 for circulatory), what do you think the .6 tells you? What about the 5 after it?
You can look it up. Type in E11.65 on the CDC’s website, or look it up in the book, and see what you find. (The site icd10data.com is another free option that many working coders use daily.) These are the same tools professionals use, and you will want them bookmarked for the rest of this series.
The answer is Type 2 diabetes mellitus with hyperglycemia. The .6 places the code in Chapter E11's "other specified complications" subcategory, and the 5 narrows it to hyperglycemia specifically. If Dale's blood sugar has been running dangerously high (and from his story, it has), this is the code that captures it. E11.9 does not. E11.65 does. Whether his record carries the right one depends on whether his provider documented the hyperglycemia and if a coder translated that documentation into the specific code. Same patient and disease, and two codes that tell two completely different stories about how well his diabetes is being managed.
This level of granularity is why the United States moved to ICD-10-CM in the first place. The system it replaced, ICD-9-CM, had been in use since 1979 and contained roughly 14,000 diagnosis codes. ICD-10-CM contains more than 70,000. Medicine had outgrown the old system. ICD-9-CM did not have codes for laterality (which side of the body), had limited ability to capture complications, and lacked the specificity that modern billing, quality measurement, and population health tracking demanded.
The World Health Organization created the base classification, ICD-10, and endorsed it in 1990. The United States adapted the diagnosis portion for clinical use, added the "CM" for Clinical Modification, and after years of delays (the implementation date was pushed back three separate times), the country finally went live on October 1, 2015. Every diagnosis documented in a clinical encounter on or after that date has been coded in ICD-10-CM.
The transition date matters here because any medical record generated before October 2015 was coded in a separate system with a separate structure. If you ever look at your own health history and see a code that starts with a number rather than a letter (like 250.00 for Type 2 diabetes), you are looking at an ICD-9-CM code. The two systems do not map cleanly onto each other, which created headaches for everyone who needed historical continuity in patient data.
Dale's clinic in Stamford coded his diabetes as E11.9, and for three years that code has been the only version of his disease that the billing system, the surveillance system, and now the AI reading his record have ever seen. Whether it still describes what is happening inside his body is a question those three characters cannot answer. A seven-character code could. Whether a coder assigned it is a different matter, and we will get to that.
In Lesson 2, we will look at what happens when the record chooses the short code over the long one, at laterality, episode of care, and the placeholder X. Dale's retinopathy has much more to teach us.
---
This is Lesson 1 of Notes from the Abstract's Medical Coding Fundamentals series. If you're joining for the first time, start here. If you've already read "The Engine and the Fuel," you know Dale. If you haven't, go read it; he'll make more sense with context.