
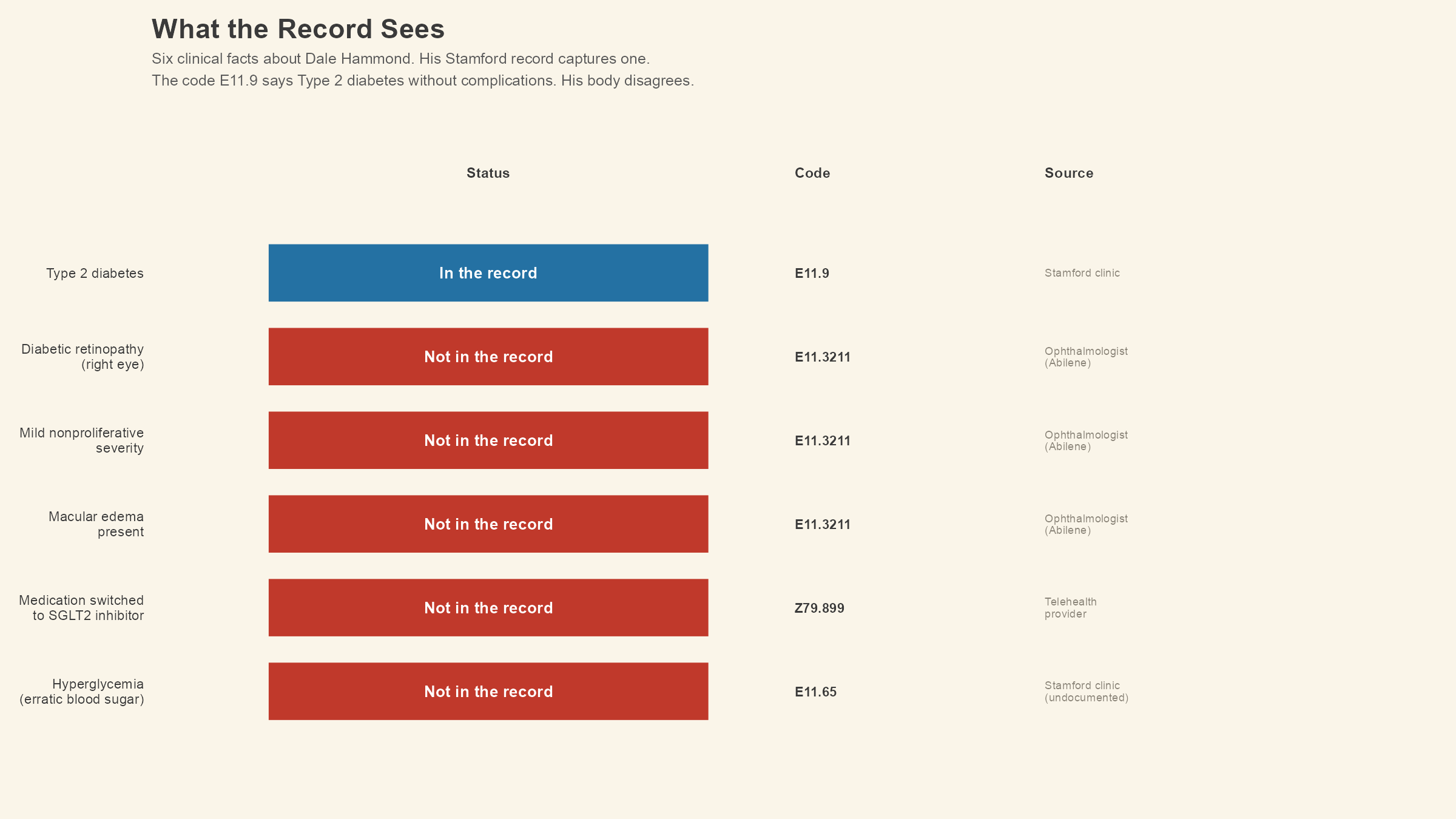
In our first lesson, we left poor Dale with a code that no longer applies to him. His local clinic assigned E11.9, Type 2 diabetes mellitus without complications, three years ago when the diagnosis was new. Since then, an ophthalmologist in Abilene found early diabetic retinopathy in his right eye, a telehealth provider switched his medication, and his blood sugar has been running high enough to worry about. The code has not changed. The disease has.
What follows is about what should have happened to that code, and about three features of ICD-10-CM that make the system capable of extraordinary precision when the documentation supports it. These are simply: laterality, episode of care, and the placeholder X.
We ended last time with E11.3211, the seven-character code for Type 2 diabetes mellitus with mild nonproliferative diabetic retinopathy with macular edema, right eye. This code appeared at the end of the lesson as an example of how far the classification can go.
Now we are going to pull it apart.
Start with what the ophthalmologist in Abilene documented. The clinical note from Dale's retinal screening says he has mild nonproliferative diabetic retinopathy with macular edema in the right eye. Every word in that sentence carries weight inside the classification system, because ICD-10-CM was designed to capture each one.
So, we covered the first four characters, E11.3, in Lesson 1; they place Dale in the category of Type 2 diabetes with ophthalmic complications. The fifth character, 2, narrows the retinopathy to mild nonproliferative. (A 3 in that position would mean severe nonproliferative. A 4 would mean proliferative. The numbers track disease severity as it worsens.) Position six, the character 1, tells you macular edema is present. A 9 in that same position would mean macular edema is absent.
The seventh character is 1, and it is doing its job the most in the entire code. Laterality is one of the features that separates ICD-10-CM from the system it replaced. The final digit tells you which eye. In the E11.32 family, 1 means the right eye, 2 means the left eye, 3 means bilateral (both eyes), and 9 means unspecified. Dale's ophthalmologist examined his right eye and found the retinopathy there, so the code ends in 1.
But, laterality doesn't just apply to just the eyes. Across ICD-10-CM, thousands of codes use a character position to distinguish right from left. Fractures, joint conditions, injuries to specific limbs, ear infections, and dozens of other diagnoses carry laterality because knowing which side of the body is affected changes clinical decisions. A torn rotator cuff in the dominant shoulder of a roughneck who works with his right hand all day is a different clinical and occupational problem than the same tear in his left. The code captures that difference if the documentation supports it.
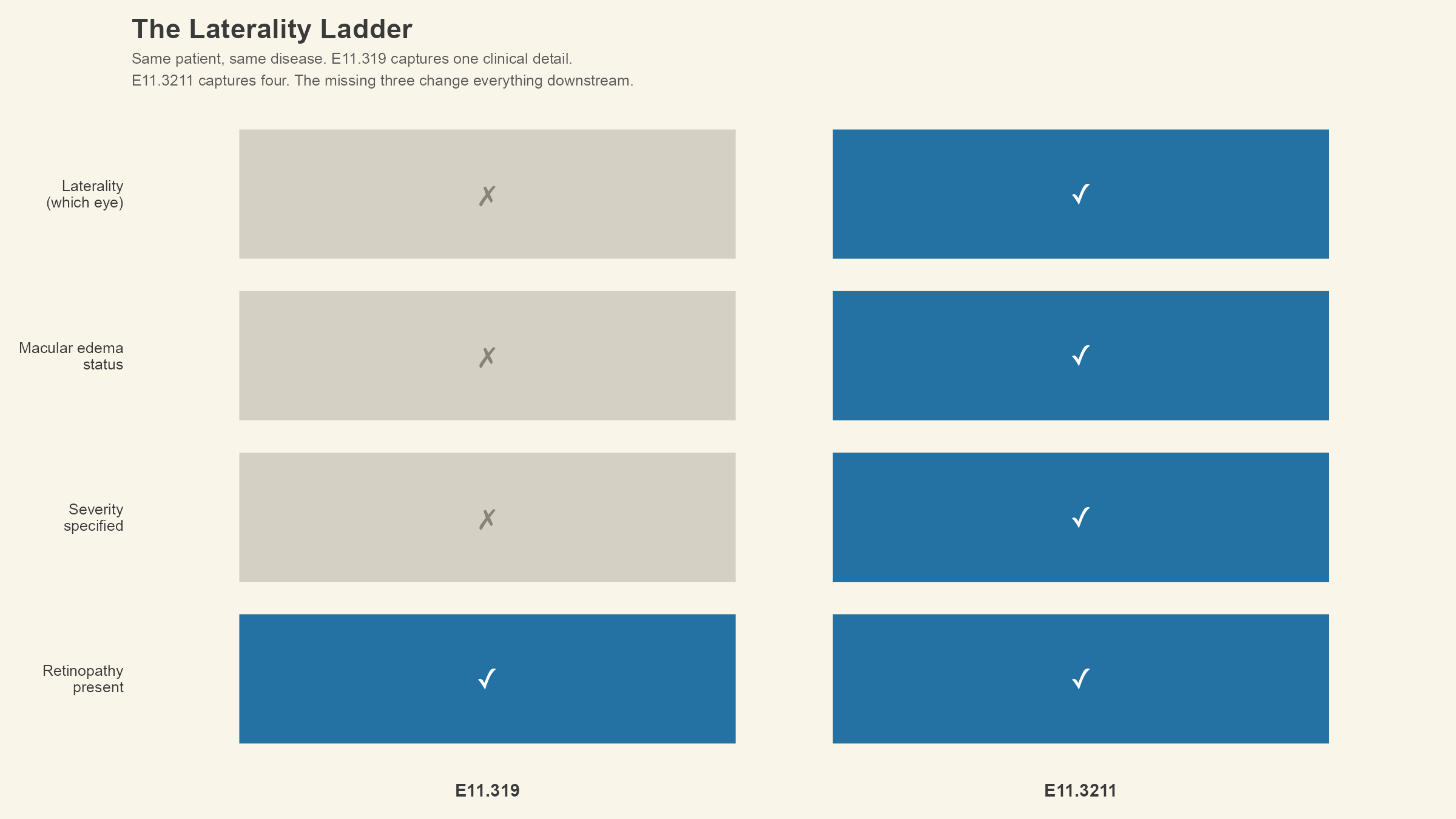
Compare E11.3211 with E11.319, the code the previous lesson introduced as the one Dale's record probably should have carried after the retinal screening. E11.319 means Type 2 diabetes mellitus with unspecified diabetic retinopathy without macular edema. Both codes acknowledge that Dale has diabetic eye disease. The distance between them is huuuuge.
E11.319 says retinopathy is present, does not specify the severity, states no macular edema, and does not identify which eye. E11.3211 says mild nonproliferative retinopathy is present, as well as macular edema, and the condition is in the right eye. One code gives you four pieces of clinical information. The other gives you just one. For a payer reviewing the claim, and a researcher counting disease prevalence, or an AI tool building a health profile, and even for the next provider who opens Dale's chart, those details that are missing change what they see and what they do with it.
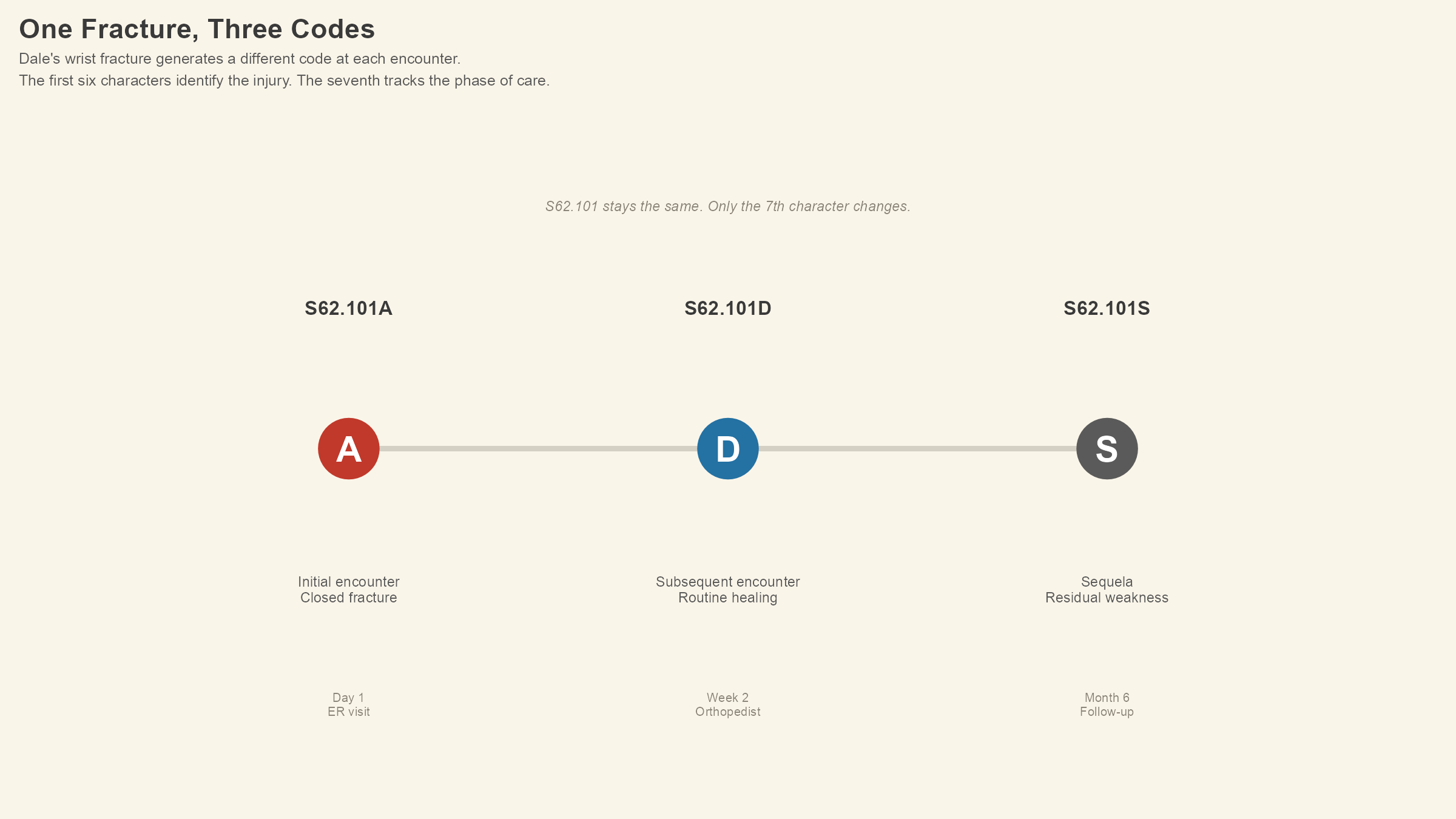
Imagine Dale has a bad week on the rig. (If you have read "The Engine and the Fuel," you know his job is physically punishing.) He catches his right hand between a pipe and a clamp, and the ER in Abilene takes an X-ray that finds a fracture in one of the carpal bones of his right wrist. The code assigned is S62.101A.
That code is a seven-character code, and every character is doing its job. S places it in Chapter 19, which covers injury, poisoning, and certain other consequences of external causes. S62 is the category for fractures of the wrist, hand, and finger bones. Characters four and five, 10, narrow it to an unspecified carpal bone fracture. The sixth character, 1, is laterality, telling you this is the right wrist. (A 2 would mean the left wrist, and a 9 would mean the documentation did not specify.)
The seventh character in this code is the letter A, and this is the second feature of ICD-10-CM we need to talk more about: the episode of care extension.
In Chapter 19 (injuries and external causes), most codes require a seventh character that tells you where in the treatment timeline this encounter falls. A means initial encounter, which is the first time the patient is seen for active treatment of this injury. The ER visit where the fracture is discovered and treated gets the A.
Two weeks later, Dale goes back to see the orthopedist for a follow-up. His fracture is healing normally; the cast is doing its job, and the provider writes routine healing into the chart. S62.101D is the code for that visit, and the only thing that changed is the seventh character, from A to D, which means subsequent encounter for fracture with routine healing. The injury is the same; the phase of care is different.
Six months later, after the fracture has healed, Dale notices his grip strength in that right hand is not what it used to be. His provider evaluates him for residual weakness, which is a typical lasting effect of the original fracture. S62.101S is the code that captures this visit. Sequela (a word that sounds like it should be plural but is not) is the medical term for a condition that is itself a consequence of a previous injury or illness, and the S in that seventh position tells you that is what the provider found. The fracture healed, but the damage left residual weakness behind.
Dale had three encounters and generated three codes from the same wrist and the same bone. The first six characters never changed. The seventh character tracked Dale's injury from diagnosis through treatment through long-term consequence, and each code tells us a different story about what was happening in his body at that moment.
If you are thinking that this level of tracking seems like overkill for a stupid wrist injury, consider what it looks like from a population health standpoint. Researchers studying workplace injuries on oil rigs need to know whether they are counting initial fractures, follow-up visits for known fractures, or long-term complications. Without the seventh character, one fracture that generated three encounters could look like three separate fractures. The episode of care extension prevents double-counting, and in surveillance data, the difference between one injury with complications and three new injuries is the difference between an accurate safety record and a distorted one.
Try one yourself. You have seen S62.101A (initial encounter), S62.101D (subsequent encounter, routine healing), and S62.101S (sequela). Look up S62.101G on the CDC's browser or on icd10data.com and see if you can figure out what the G tells you before you read the description. The first six characters are the same fracture, the same wrist, the same patient. Only the seventh character changed. What happened?
Uh huh.
The answer is subsequent encounter for fracture with delayed healing. The fracture did not heal on schedule, and the G captures that clinical fact in a single character. D and G both describe follow-up visits for the same fracture, but one says healing went as expected and the other says the opposite. A provider reading the record, a payer evaluating the claim, and a researcher tracking outcomes get different information from each.
Now look at a different code, W01.0XXA. If you type that into the browser, you will find it means fall on same level from slipping, tripping, and stumbling without subsequent striking against object, initial encounter.
W01.0XXA is an external cause code, used alongside the injury code to document how the injury happened. (Dale's wrist fracture would carry the S62 code for the fracture itself and an external cause code like this one to explain the mechanism.)
The two X's in the middle of W01.0XXA are placeholder characters, and they are the third feature of ICD-10-CM we need to cover. W01.0 is only four characters long, but ICD-10-CM needs the seventh character (A, for initial encounter) to land in the seventh position, not the fifth. The X's fill positions five and six so that the A stays where the system expects to find it.

Placeholder X's are the system's way of preserving the structural logic of the code when a certain category does not need characters in every position. They don't have any clinical meaning of their own, because they're just scaffolding. When you see an X in an ICD code, what it's telling you is that the character position exists in the code's architecture, that no specific clinical information was needed there, and that the characters after it still need to be in their designated slots.
You will encounter placeholder X's most often in Chapter 19 (injuries) and Chapter 20 (external causes), where codes frequently need a seventh character for episode of care, even when the base code is shorter than six characters. If a code requires a seventh character and the base code is only three, four, or five characters long, X's fill the positions in between. W01.0XXA has two of them. Some codes have one. The rule is consistent. Every X is a seat-holder, and the meaningful character sits at the end.
A small mechanical detail, but one that trips up new coders more often than you might expect. Leaving out a placeholder X means submitting a code that the system will reject, because the seventh character has landed in the wrong position. The claim gets denied, then the coder gets a rejection notice, and then the whole shebang has to be corrected and resubmitted. In a high-volume coding environment, this adds up. In a small clinic where the margin for error is already so incredibly thin, each one is enough to keep the coding manager up at night.
So the system can capture laterality, severity, macular edema status, episode of care, and mechanism of injury, all within seven characters. ICD-10-CM was built to pack that much clinical information into that small a space. The 70,000-plus codes in the classification are not redundant; they are the system trying to describe every clinically meaningful variation of every diagnosis a provider can document.
The question that follows has to do with what happens when the documentation does not support the code. If the classification can go seven characters deep, and each character adds clinical meaning that changes what a payer approves, what a researcher counts, and what an AI flags, what happens when the record stops at three?
Dale's ophthalmologist in Abilene documented mild nonproliferative diabetic retinopathy with macular edema in the right eye. The documentation supports E11.3211. If a trained coder had access to that note and coded the encounter, E11.3211 is the code that would have been assigned. The system worked the way it was designed to work.
The problem is what happens next. The ophthalmologist's office uses a different electronic health record than the Stamford clinic, and the two systems do not share data automatically. So how does that retinal screening result get into Dale's primary care record? Through a fax, or a referral note, or an interface between two EHR systems that may or may not talk to each other. If the finding never arrived, or arrived and sat in an inbox, or arrived and was scanned into the chart as an unstructured PDF that no one indexed (and if you have worked in a small clinic, you know how often that happens), the Stamford clinic's record still reads E11.9.
The classification system did its job, but, once again, the documentation pipeline did not.
When a clinic has a credentialed coder on staff, that person's job is to review the clinical documentation, identify every codeable diagnosis, and assign the most specific code the documentation supports. At a facility the size of Dale's clinic in Stamford (open weekdays, eight to five, closed for lunch), the person handling the coding may also be handling the front desk, the scheduling, the insurance verification, and the billing. Coding specificity is not a priority when the phone is ringing and three patients are waiting to check in. E11.9 is faster than E11.3211, and the claim goes through either way.
Effort and intelligence are not what is wrong here. People working in these clinics are doing the best they can with what they have, but the failure is structural. E11.9 is a valid, billable code for a patient who has Type 2 diabetes, and submitting it will not trigger a denial. The payer will process it, and the claim will pay. Nothing in the reimbursement system flags the difference between E11.9 and E11.3211 as a problem, because both codes are valid for their respective clinical scenarios. When the system accepts the less specific code without complaint, the clinical detail that a seven-character code could have captured vanishes from the record.
Over time, this stacks up like cards. Every E11.9 assigned to a patient whose documentation supports a more specific code is a piece of clinical information that the billing system, the surveillance system, and every downstream tool reading that record will not see. Multiply Dale by the roughly 60 million Americans who receive care at rural facilities, and the data loss is not a rounding error.
ICD-10-CM contains 117 codes under E11 alone, 87 of them billable, the rest serving as category headers that organize the billable codes underneath. Each one describes a different permutation of Type 2 diabetes and its complications, specifying which organ system is affected, how severely, with or without secondary findings, in which eye or which limb or which nerve. The system was built for this. Whether the infrastructure that feeds it can keep pace is a separate question, and one that Lesson 1 and "The Engine and the Fuel" have both been circling.
Dale's record still says E11.9. His retinopathy is in the ophthalmologist's chart in Abilene, his medication change lives in the telehealth system's records, and his blood sugar readings are on his phone. Somewhere in those scattered fragments is a seven-character code that describes what is happening inside his body with a precision the healthcare system was specifically designed to achieve.
The Stamford clinic never assigned it.
In Lesson 3, we will step back from Dale's codes and walk through the 21 chapters of ICD-10-CM, but we're not going to memorize them, instead we're just going try to understand the organizing logic that determines where every diagnosis in the system lives. If Lesson 1 taught you the anatomy of a single code and Lesson 2 taught you what that code can become, Lesson 3 will teach you where to find it.
This is Lesson 2 of Notes from the Abstract's Medical Coding Fundamentals series. Lesson 1 is here. If you are following along with the ICD-10-CM browser at icd10cmtool.cdc.gov or icd10data.com, try looking up a few of the codes from this lesson yourself. The more you use the tools, the less foreign the codes will feel.